Архитектура нейроконтроллера
В предыдущем примере описывалась нейронная сеть с одним выходом. В
компьютерных играх используется несколько иная архитектура - сеть,
построенная по принципу "победитель получает все". Такие архитектуры
полезны в том случае, если выходы должны быть разделены на несколько классов
(рис. 5.9).
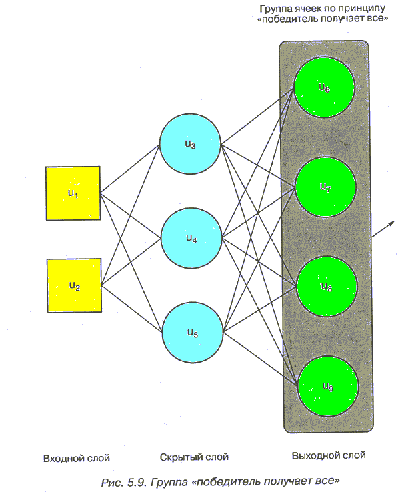
В сети, созданной по принципу "победитель получает все", выходная с
большей суммой весов является "победителем" группы и допускается к
действию. В рассматриваемом приложении каждая ячейка представляет определяет
поведение, которое доступно для персонажа в игре. В качестве примеров
поведение можно назвать такие действия, как выстрелить из оружия, убежать,
уклониться. Срабатывание ячейки в группе по принципу "победитель получает
все" приводит к тому, что агент выполняет определенное действие. Когда
агенту вновь позволяется оценить окружающую среду, процесс повторяется. На
рис. 5.10 представлена сеть, которая использовалась для тестирования
архитектуры и метода выбора действия.
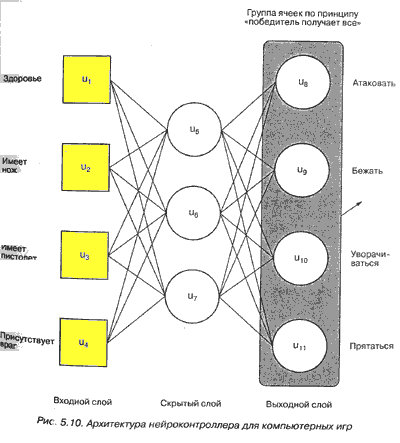
Четыре входа обозначают "здоровье
персонажа" (0 " плохое, 2 - хорошее), "имеет нож" (1, если персонаж имеет
нож, 0 -противном случае), "имеет пистолет" (1, если персонаж имеет
пистолет, 0 -противном случае) и "присутствует враг" (количество врагов в
поле зрения). Выходы определяют поведение, которое выберет персонаж.
Действие "атаковать" приводит к тому, что персонаж атакует врагов в поле
зрения, "бежать" вынуждает персонаж убегать, "уворачиваться" приводит к
произвольному движению персонажа, а "прятаться" вынуждает персонаж искать
укрытие. Это высокоуровневые образы поведения, и предполагается, что
подсистема поведения будет выбирать действие и следовать ему.
Выбранная здесь архитектура (три скрытые ячейки) была определена способом проб и ошибок. Три скрытые ячейки могут быть обучены для всех представленных примеров со 100% точностью Уменьшение количества ячеек до двух или одной приводит к созданию сети, которая не может правильно классифицировать все примеры.
Обучение нейроконтроллера
Нейроконтроллер в игровой среде представляет собой постоянный элемент персонажа. Дальше мы обсудим обучение нейроконтроллера в режиме реального времени.
Обучение нейроконтроллера состоит в предоставлении обучающих примеров из небольшой группы желательных действий. Затем следует выполнение алгоритма обратного распространения с учетом желаемого результата и действительного результата. Например, если персонаж имеет пистолет, здоров и видит одного врага, желаемое действие - атаковать. Однако если персонаж здоров, имеет нож, но видит двух врагов, то правильное действие - спрятаться.
Данные для тестирования
Данные для тестирования представляют собой несколько сценариев с набором действий. Поскольку требуется, чтобы нейроконтррллер вел себя так же, как настоящий человек, мы не будем обучать его для каждого случая. Сеть должна рассчитывать реакцию на входы и выполнять действие, которое будет похожим на обучающие сценарии. Примеры, которые использовались для обучения сети, представлены в табл. 5.1.
Таблица 5.1. Примеры, которые используются для обучения нейроконтроллера
| Здоровье | Имеет нож | Имеет пистолет | Враги | Поведение |
| 2 | 0 | 0 | 0 | Уворачиваться |
| 2 | 0 | 0 | 1 | Уворачиваться |
| 2 | 0 | 1 | 1 | Атаковать |
| 2 | 0 | 1 | 2 | Атаковать |
| 2 | 1 | 0 | 2 | Прятаться |
| 2 | 1 | 0 | 1 | Атаковать |
| 1 | 0 | 0 | 0 | Уворачиваться |
| 1 | 0 | 0 | 1 | Прятаться |
| 1 | 0 | 1 | 1 | Атаковать |
| 1 | 0 | 1 | 2 | Прятаться |
| 1 | 1 | 0 | 2 | Прятаться |
| 1 | 1 | 0 | 1 | Прятаться |
| 0 | 0 | 0 | 0 | Уворачиваться |
| 0 | 0 | 0 | 1 | Прятаться |
| 0 | 0 | 1 | 1 | Прятаться |
| 0 | 0 | 1 | 2 | Бежать |
| 0 | 1 | 0 | 2 | Бежать |
| 0 | 1 | 0 | 1 | Прятаться |
Данные, приведенные в табл. 5.1, были переданы сети в произвольном порядке
во время обучения с помощью алгоритма обратного распространения. График
снижения средней ошибки показан на рис. 5.11
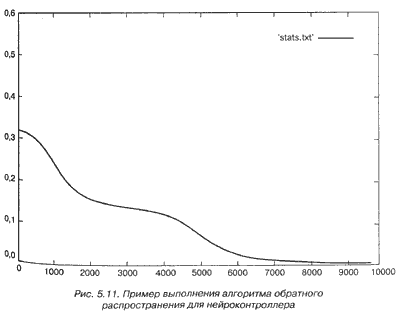
В большинстве случаев сеть успешно проходит обучение на всех представленных
примерах. При некоторых запусках один или два примера приводят к
неправильным действиям.
Программа на С